GPUコンピューティングとNVIDIA Ampereアークテクチャ
GPUもVTにお任せください!
ビジュアルテクノロジーは、HPCシステムのハードウェアとソフトウェアのスぺシャリストです。メニーコアCPUによるクラスタ構成などはもとより、GPUを含めた各種アクセラレータを搭載した、多目的でハイパフォーマンスなシステムもお任せください。
NVIDIA社のGPGPU (General-purpose computing on graphics processing units; GPUによる汎用計算)または「GPUコンピューティング」による、数値計算やシミュレーションの高速化、Deep Learning手法によるAI/機械学習、ビックデータ解析など、様々な研究開発に最適なコンピュータシステムをご提案いたします。ご利用になるアプリケーションに応じた、適切なGPUの選択と、CUDAやコンパイラ、OpenACC、MPIライブラリ、Python環境、Docker等のコンテナ環境といったミドルウェアや各種APIなど、システム構築とサポートをご提供いたします。
もちろん、プリ/ポスト処理で必要な各種ビジュアライゼーション用途もご相談ください。
NVIDIA GPU製品
NVIDIA Ampere アーキテクチャ Tensor Core GPU
最新のラインアップ
- コンピューティングボード:
倍精度浮動小数点演算を必要とする数値計算やシミュレーション用途
A100/A30
- プロフェッショナル・ゲーミング グラフィックスボード:
AI推論/機械学習、データサイエンス用途、グラフィックス/vGPU用途
A40/A16 /A10 /A2 (vGPU対応)
RTX A6000/A5000/A4500/A4000/A2000
GeForce RTX3090/3080/3070/3060


NVIDIA Ampere アーキテクチャ Tensor Core GPU
NVIDIA H100
NVIDIA H100 GPUについて
大規模なAIやHPCにおいて前世代のNVIDIA A100と比較して桁違いの性能の飛躍を実現するために設計されたNVIDIAの第9世代のGPUです。
最先端のTSMC 4Nプロセスを使用して、800億のトランジスタを搭載しています。
世界最大かつ最も強力なアクセラレータであるH100は、革新的なTransformer Engineや巨大なAI言語モデル、ディープ レコメンダー システム、ゲノミクス、複雑なデジタル ツインを進化させるための高い拡張性を備えたNVIDIA NVLink相互接続などの画期的な機能を備えています。
第4世代のNVIDIA NVLinkは、マルチGPU IOの総帯域幅900GB/秒を実現。A100のNVLinkの1.5倍、PCIe Gen5の7倍に達します。
H100は、PCIe Gen5をサポートする最初のGPUであり、かつ3TB/sのメモリ帯域幅を実現するHBM3を利用する最初のGPUでもあります。
製品仕様
こちら をご覧ください。
-
NVIDIA H100 GPU 主要機能概要
新しい第4世代Tensorコアは、streaming multiprocessor(以降SM)自体の高速化、SM数の増加、クロック周波数の向上等により、
A100との比較で最大6倍高速化されています。FP64、FP32の演算性能がA100比で3倍に向上
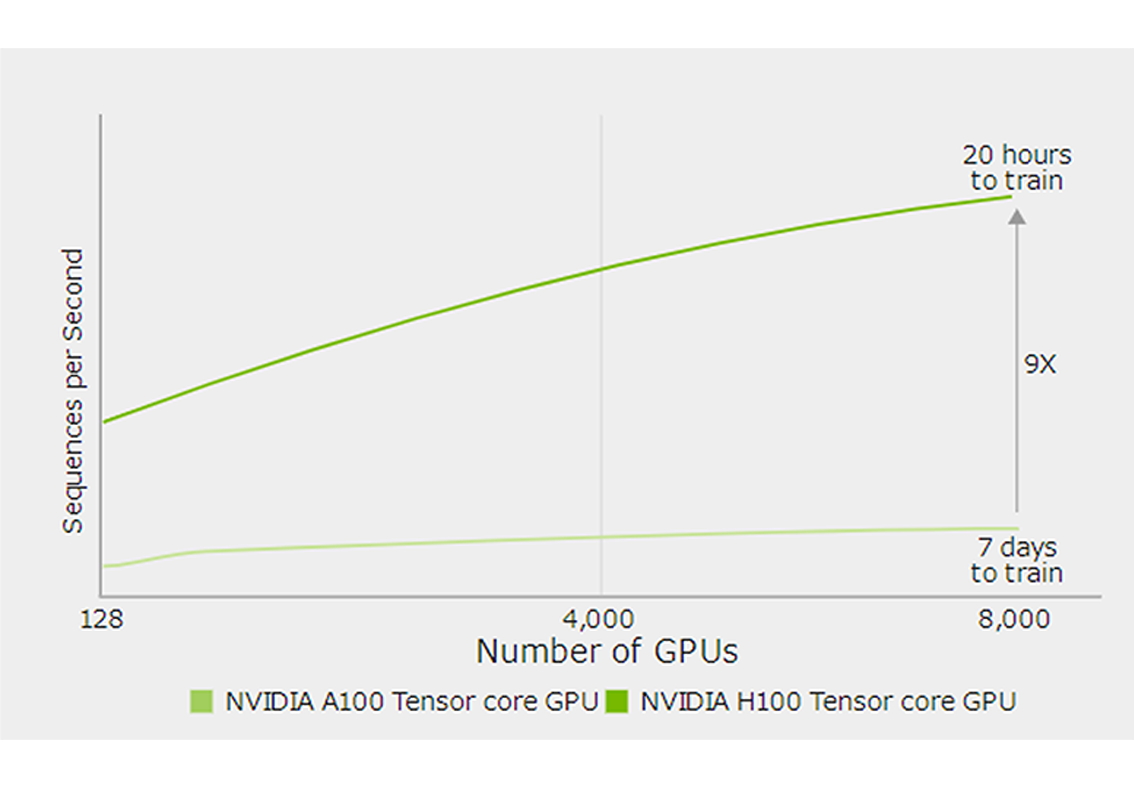
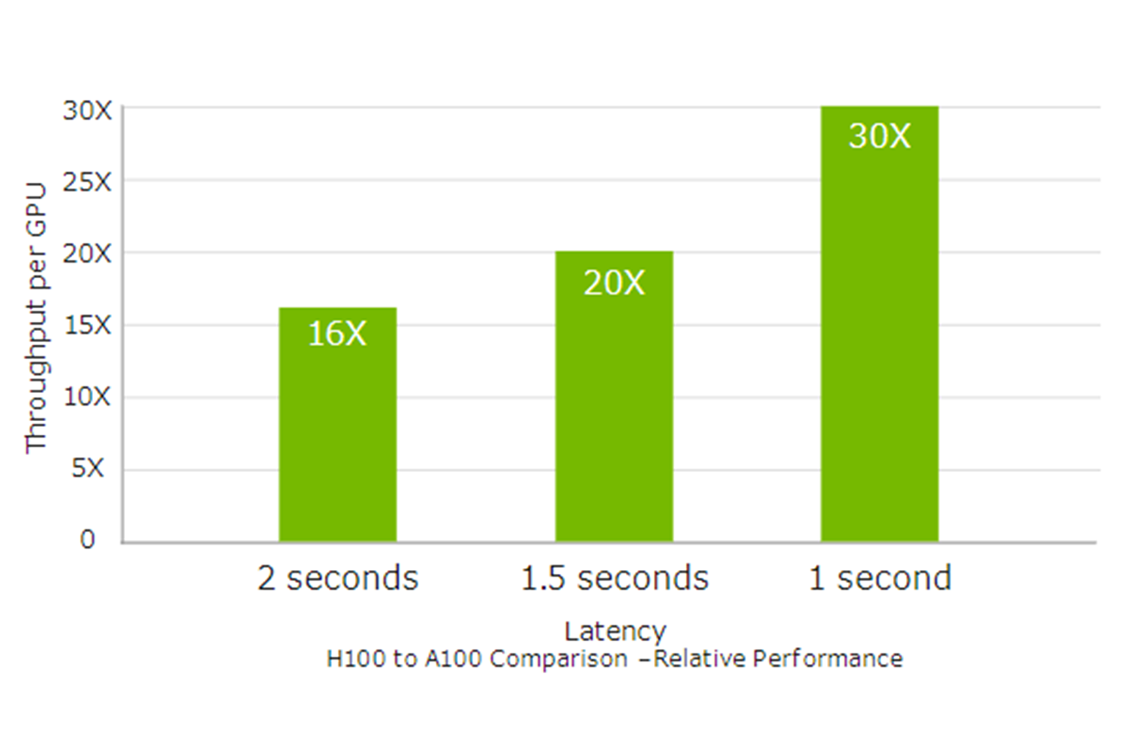
前世代のA100と比較して、大規模言語モデルのAIトレーニングを最大9倍、AI推論を最大30倍高速化します。
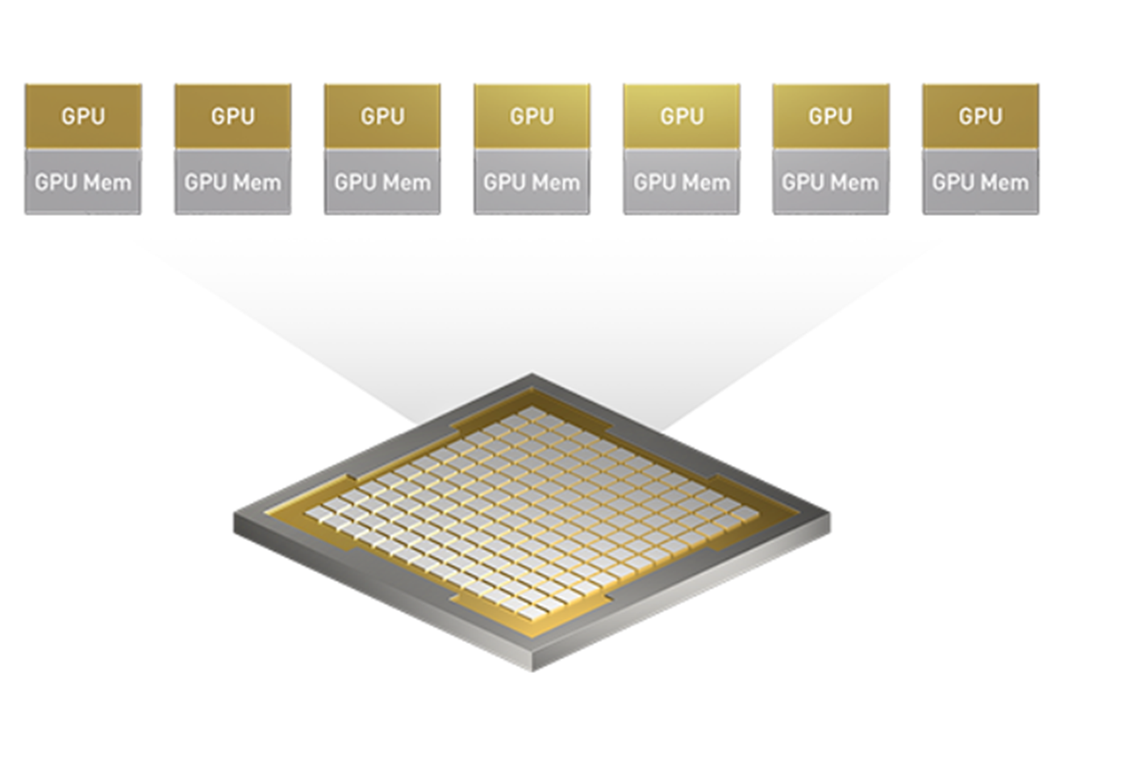
第2世代マルチ インスタンスGPU(MIG)搭載
H100は最大7つのGPUインスタンスをサポートします。
H100のMIGはA100と比較して、GPUインスタンスあたりの計算能力が約3倍、メモリ帯域が約2倍に向上しています。
GPUをワークロードに合わせて分割して、効率的に利用することができます。最大7つのジョブを同時に実行することができます。
導入をご検討の場合はお気軽にご相談ください
構築から導入、保守までワンストップでのサポートが可能です
また、エンジニアチームは、提案部門と構築‧導入‧保守部門が一体となっていますので、お客様に寄り添った柔軟な対応が可能です。
- 導入コンサルテーション
- HPCプラットフォーム構築サービス
- 保守サービス
- 運用支援サービス