【ベンチマーク】 NVIDIA GB10搭載 ミニスーパーコンピュータ
2026.01.21
AI用途だけではない
量子シミュレーション用としても活用できる
NVIDIA DGX Spark™ベースのスーパーコンピュータ
ベンチマークで性能比較
AIの開発や研究などに向いている、手のひらサイズでありながら高性能なコンピュータが人気となっています。
弊社では、NVIDIA DGX Spark™ベース製品とGPUワークステーションを使って、
「GB10」とNVIDIA GPU3世代「RTX3090」「RTX6000Ada」「H100」を、
量子計算シミュレーション(Qiskit + cuQuantum Appliance)と
大規模言語モデル推論(Ollama + gpt-oss)の2点で性能比較を行いました。
使用したハードウェア

GPUとの比較表
| GB10 | RTX3090 | RTX6000 Ada | H100 | |
|---|---|---|---|---|
| 世代/アーキテクチャ | Grace Blackwell | Ampere | Ada Lovelace | Hopper |
| VRAM容量 | 128GB | 24GB | 48GB | 80GB |
| メモリ帯域 | 273 GB/s | 936 GB/s | 960 GB/s | 3,350 GB/s |
| FP16/Tensor性能(公称) | 1PFLOPS(FP4) | 935.6 TFLOPS(FP16) | 200 TFLOPS(FP16 Tensor) | 1,000+ TFLOPS (FP16 Tensor) |
| 単体消費電力 (w) | 240w | 350w | 300w | 350w |
| システム合計消費電力 (w) | 240w | 1000w~ | 1000w~ | 1500w~ |
| Cost ($) | 4,000 | 1,500 | 7,000 | 7,000 |
| Cost ($) (≧128GB) | 4,000 | 9,000 | 21,000 | 14,000 |
※価格は、2025年12月時点での概算
用途・bit数に限りはあるが、量子計算向けにも使用可能
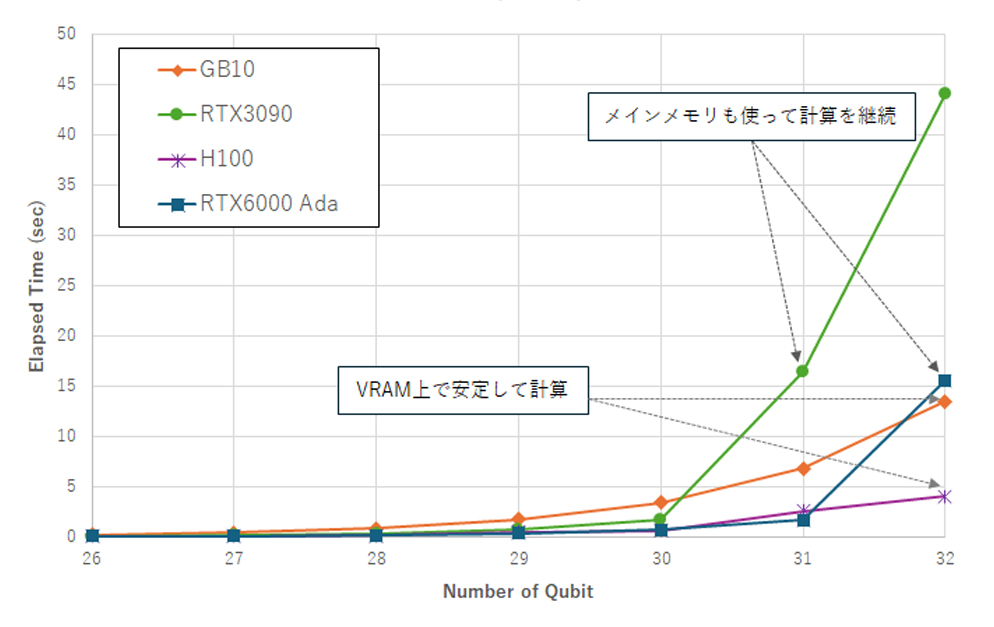
IBM Qiskit AerシミュレータとNVIDIA cuQuantum/cuStateVec(cusvaer)を用いて、
GHZ状態(Greenberger–Horne–Zeilinger状態)生成回路の
実行性能評価を目的としたスクリプトを作成しベンチマークを実施。
NVIDIA cuQuantum Applianceに含まれるQiskit-Aer GPU backendは
GPUメモリとCPUメモリを合わせてstatevectorを保持しようとしますが、
ユニファイドメモリを採用しているDGX Sparkベース製品では、32qubitを上限に計算がストップしてしまいました。
DGX Sparkベース製品単体のGPU性能は特定bit領域において必ずしも優位とは言えませんでした。
しかし、GPUワークステーション全体のコストパフォーマンスに注目し、導入コスト・消費電力を比較すると
DGX Sparkベース製品が32bitまで安定した計算が可能だった事実は無視できません。
測定条件
| バックエンド | cusvaer_simulator_statevector |
| 計算時間 | backend.run(circuit, shots=1)の実行時間 |
| 浮動小数点数精度 | 倍精度 |
| 各回路実行時の測定ショット数 | 4096ショット |
| 量子ビット数(nbits) | 10ビットから1ビットずつ増加 |
GHZベンチマーク
※倍精度での計算
120Bのモデルが無理なく載る VRAM 128GBはコスパ◎
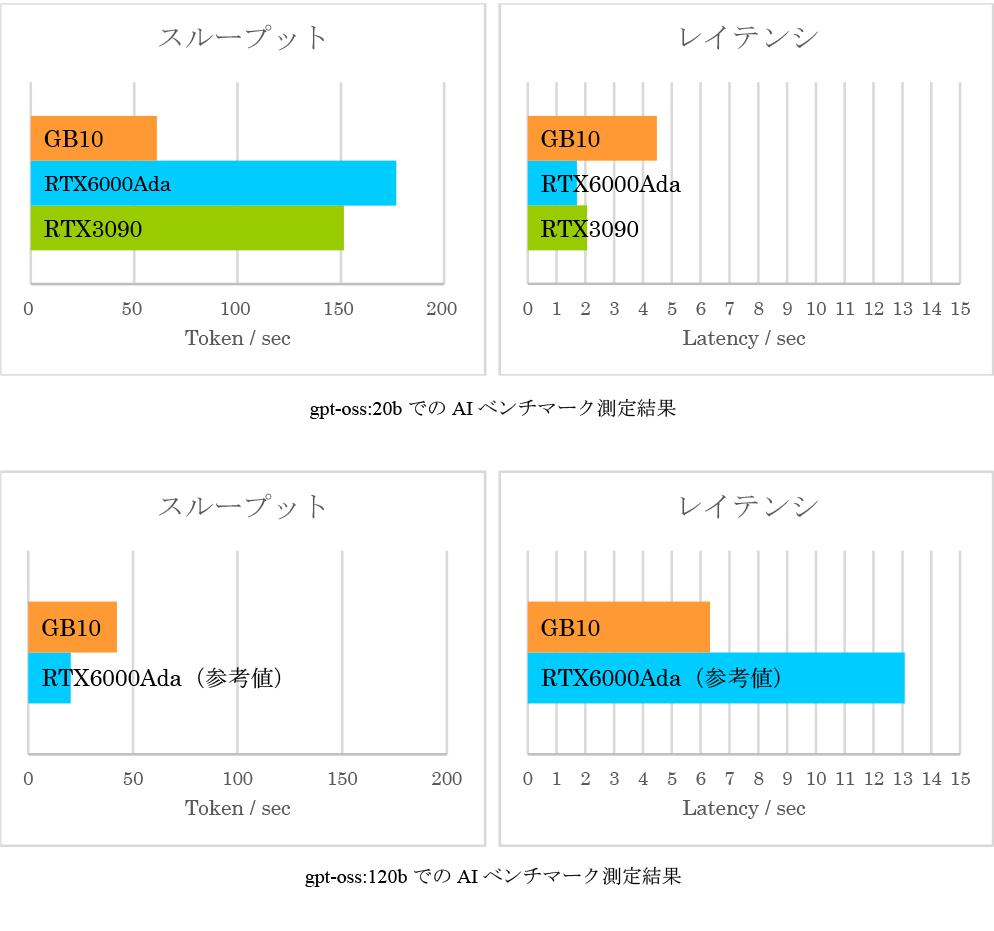
Ollama推論エンジンとLLM(gpt-oss:20b)を用い、GPUワークステーションの推論性能を
1) token/sec(スループット)と 2) first-token latency(レイテンシ)を中心に比較しました。
120Bモデルでの測定が興味深い結果となりました。
GB10はGPU VRAM上にモデルを展開できるため、
6.32秒のレイテンシ、42.31token/secと実用的な性能を維持したのに対し、
RTX6000 AdaはVRAMに収まらずRAM越し動作となり、
レイテンシが 13秒台、token/secもGB10の半分以下に低下しました。
20Bのような中規模モデルではAdaが最速であっても、
大規模モデルの安定運用や推論性能をシステムレベルで確保できるのはGB10であり、
モデルサイズが大きくなるほどその有用性が顕著になると言えるようです。
推論条件
| 推論エンジン | Ollama |
| モデル | gpt-oss:20b(20億パラメータ、13GB) gpt-oss:120b(120億パラメータ、63GB) |
| 出力トークン数 | 256トークン |
| 浮動小数点精度 | Ollama内部仕様に準拠(基本FP16) |
| 試行回数 | 7回(初回推論のオーバーヘッドは無視) |
性能測定
手軽な「サイズ」「価格」「納期」で始める AI/量子の研究・開発
特にAI推論では、120Bクラスの大規模モデルをVRAM上で直接処理できる点が大きな差別化要素であり、
メモリ越し動作を強いられる他のGPUとは安定性・性能ともに明確な違いが出ました。
量子シミュレーションでも、32bit付近における挙動は特定実装の制約の影響を受けますが、
DGX Sparkベース製品自体は大規模ワークロードを受け止めるための電源・冷却・筐体設計や
周辺ソフトウェアスタックを備えており、“単体GPU性能” だけでは測れない強みがあります。
現状、規模が拡大し続けるAI/量子の研究や開発を、
DGX Sparkベース製品のような統合プラットフォームから手軽に始めてみてはいかがでしょうか。
次のようなケースにおすすめです
● AI/量子を始めるPoCに
● AI/量子の人材育成用に
● 自社向けAI開発・運用に
● 企業のプロジェクト用に
● 大学・研究室に
● 残予算の使い道に
弊社では、HP、DELL、ASUS、MSI、Supermicro 各社 DGX SPARK OEM製品を取り扱っております。
ご興味がございましたら、ぜひお気軽にお問い合わせください。
▼ 以下のページでも、NVIDIA DGX Spark™ベースAI専用スーパーコンピュータについて、ご紹介しております。
https://www.v-t.co.jp/news/personal-ai-supercomputer/