POWER PLATFORM
Powerプラットフォーム
「POWER9は、AI時代の全方位プロセッサ」
高性能なAIインフラストラクチャー
IBM社のPOWERプロセッサは、RISCアークテクチャの1つであるPowerアークテクチャをベースとした製品シリーズです。現在の最新CPUはPOWER9です。
広帯域メモリバンド幅とPCIe Gen4、CPUとGPU間をNVLinkで直結したアーキテクチャにより、Deep
LearningやHPC分野での高性能な計算機環境として活用可能です。また、ファームウェアであるPOWERハイパーバイザの機能を利用して物理プロセッサを論理的に分割して利用する機能により(マイクロ・パーティショニングとダイナミックLPAR)を活用したクラウドインフラ基盤用途などにも対応可能です。

IBM PowerAI Platform
特にAI/Deep Learning環境への活用に関しては、IBM社がPower環境向けに最適化したDeep Learningフレームワークをパッケージ化したPowerAI(Watson Machine Learning Accelerator)、及びディープ・ラーニングに特化したGUIベースの画像解析アプリケーションであるPowerAI Visionを利用することができます。
PowerAI / PowerAI Visionのご利用は、NVIDIAのGPUが搭載されているIBM Power System AC922、及びIC922が前提となります。
VTでは、Linuxを使ったHPC分野とAI / 機械学習分野での活用を念頭に、POWER9製品をご提案しています。
FEATURESIBM POWER9の特徴
HPC分野や、クラウドインフラ基盤への利用をターゲットにリリースされたIBM POWER9は、非常に強力なメニーコアのプロセッサです。更に、PCIe Gen 4.0、OpenCAPI、CPUとGPUを直接接続するNVLinkといった新世代の入出力アーキテクチャをサポートしています。
これらによって、既存のPCIe Gen3ベースのx86サーバと比較してI/O処理能力 最大9.5倍を実現しています。
「画期的なIBM POWER9プロセッサー・チップ」
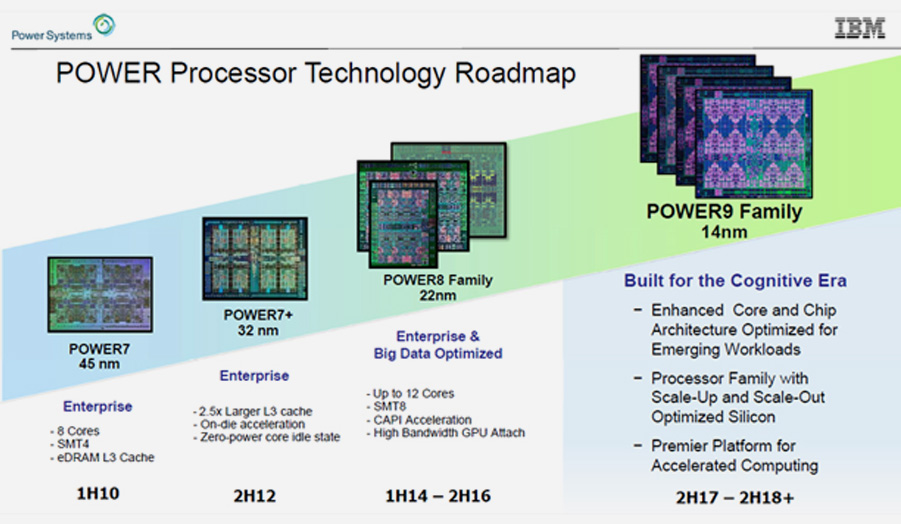
POWER9は、以下の4つのバリエーションで登場しました。
スケールアウト型
Power Systems S914, S922, S924に搭載
12コア SMT8、
24コア SMT4タイプ
スケールアップ型
Power Systems E980, E950に搭載
12コア SMT8、
24コア SMT4タイプ
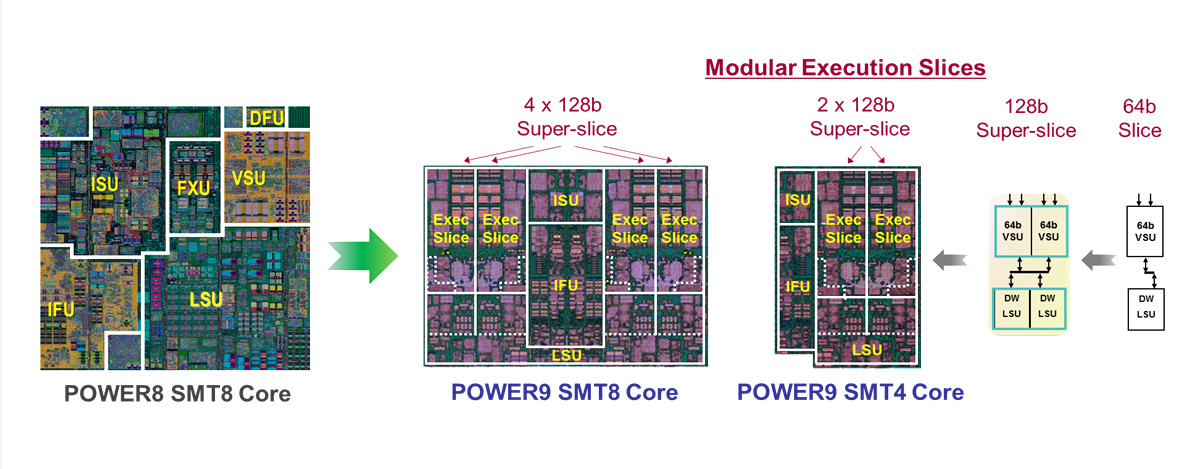
POWER9には、1コアで複数のスレッドが稼働する並列マルチスレッディング(SMT:Simultaneous Multithreading)で2つのタイプがあります。LinuxのSoE(Systems of Engagement:ユーザが活用するシステム)ワークロード向きの4スレッドタイプと、IBM i、AIXならびにLinuxのSoR(Systems of Record:組織内の基幹系システム)ワークロード向きの8スレッドタイプです。これは、分岐や繰り返しが比較的少ないHPCやAI向けのプログラムは4スレッド/Coreで、多数のクライアントからの要求を受け付け、多様な処理を必要とするアプリケーションは8スレッド/Coreで、という用途の違いを想定したものです。前者は「HPC計算用途」、後者は「クラウドインフラ基盤用途」となります。どちらの場合でも、チップ全体での並列実行スレッド数は96スレッドです。
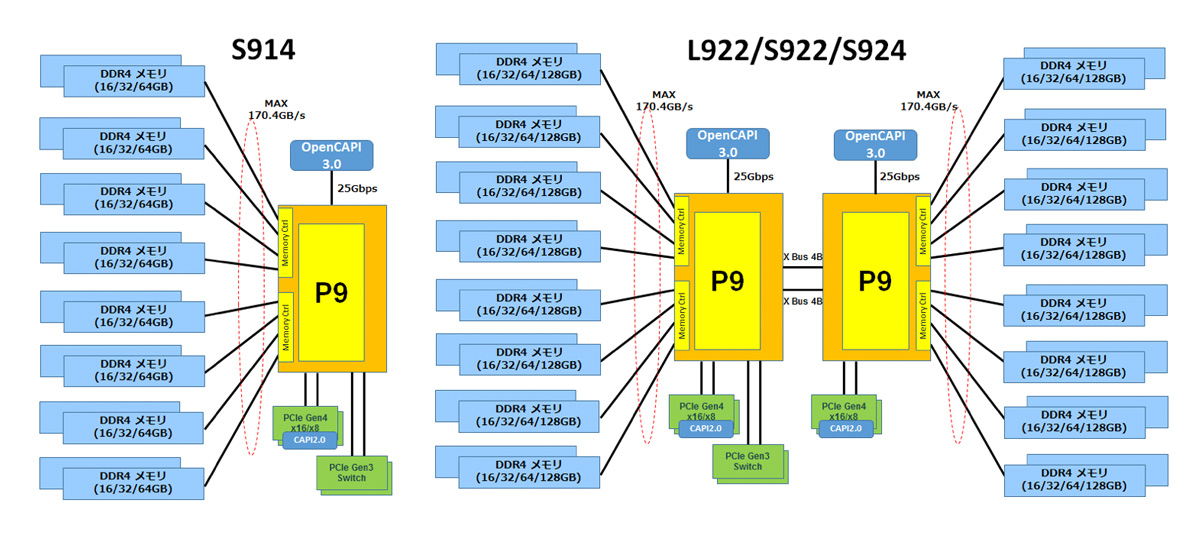
メモリの接続方法も2タイプがあり、DIMMを直結するスケールアウト型と、バッファード・メモリを経由して大容量のDIMMが接続可能なスケールアップ型があります。
POWER9の2つの
メモリ・アキテクチャ
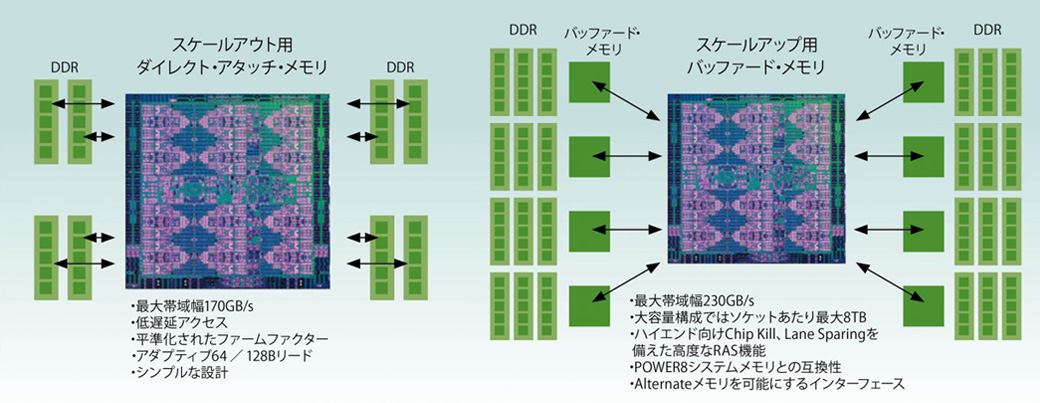
現在、クラウドインフラ基盤用途では、物理プロセッサ最大16ソケット構成も可能です。
HPCやエンタープライズAIに最適なサーバとされているPower Systems AC922では、2ソケット構成で、1ソケット当たり、16または20コア SMT4(最大80スレッド)で最大2TBメモリが利用できます。

CALCULATION APPLICATIONHPC計算用途としての特徴
広帯域メモリバンド幅
1ソケットあたり 170.4GB/sのメモリバンド幅を持ち、帯域依存の高いHPCアプリケーションのプログラムを高速に実行可能です。
SMT4対応プロセッサを搭載
コアあたり4つのスレッドを同時に実行できる構成のCPUは、マルチスレッド対応プログラムで高い並列処理性能を持つとともに、分岐や繰り返しが比較的少ないHPCやAI向けのプログラムの実行との両立が可能です。
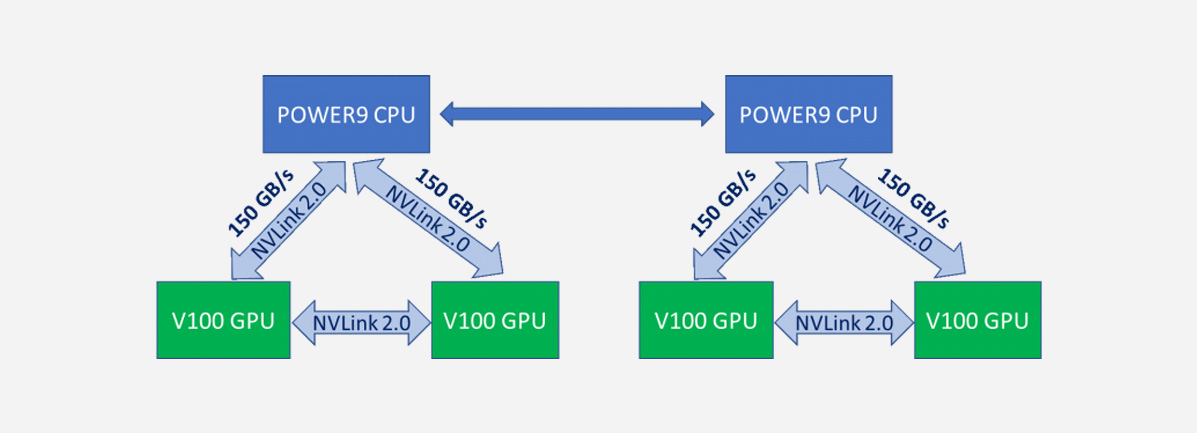
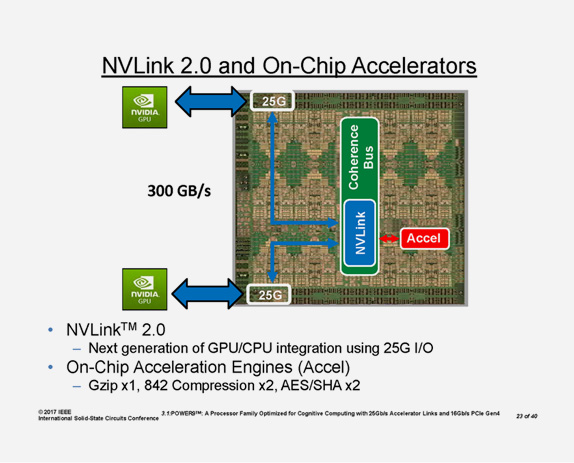
CPUとGPUを直結する
NVLinkを搭載
AI、ディープ・ラーニング、GPGPUを用いるHPCといったワークロードでは、GPUとCPU(メインメモリ)間のデータ転送の速度が重要です。
CPUとGPUを直結するNVLinkを搭載したモデルは、POWER9プロセッサとNVIDIA Tesla V100との間で150GB/sという高速な通信を実現します。
膨大なデータ量の処理においてもGPUが待つことなく、処理を続けることができます。
GPU間のNVLinkしかサポートしないx86アークテクチャと比べ、非常に高い性能を発揮することができます。
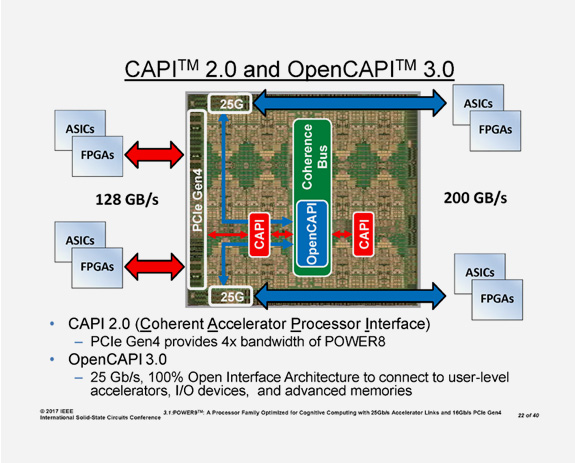
非常に大きなバンド幅、高いI/O性能
PCIe Gen4.0 の48レーン(192GB/s)を実装
OpenCAPI(Coherent Accelerator Processor Interface)2.0による実効128GB/sで、各種デバイスを接続。
IBM独自技術の 48レーン(25Gb/sリンクで300GB/s)アタッチバスを実装
| ・ | OpenCAPI3.0による実効200GB/sで、ASICやFPGAを接続 |
|---|---|
| ・ | NVLink2.0による300GB/sで、GPUを接続 |
OTHERその他の特徴
SMT4/SMT8の選択が可能
マルチスレッド実行は、メモリ入出力のレイテンシを遮蔽してくれることからスループットが向上する場合があります。
コア当たりあたり最大8スレッド構成のCPUは、多数のクライアントからの多様な処理を実行するような場合に有効です。
HPC用途であっても、データの依存関係のまったくないHPCパラメータスタディー計算のような場合には、一度に計算できるコア数(スレッド数)が多ければ多いほど性能向上に寄与します。コア当たり最大4スレッド構成のCPUは、分岐や繰り返しが比較的少ないHPCやAI向けのプログラムの実行に向きます。
POWER9アーキテクチャの世界では、ご利用方法に合わせたCPU及びシステムを選択することができます。
メモリ接続方法毎のメモリバンド幅
データの依存関係のあるHPC計算には、メモリバンド幅が大きければ大きいほど性能向上に大きく寄与します。
クラウドインフラ基盤への利用で、多くの仮想マシンを集約したり、多数のクライアントからの要求を受け付けて多様な処理を行う場合も、もちろん大きなメモリバンド幅が有効です。
L922、S922、S924はシステムあたり 340.8GB/sのメモリ帯域、AC922、S914は 170.4GB/sのメモリバンド幅を持ちます。
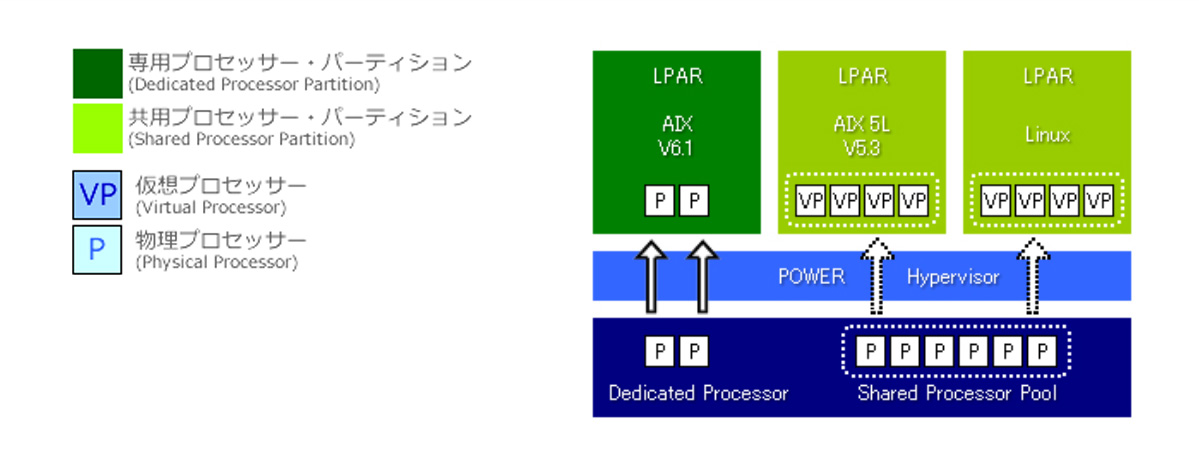
Micro-Partitioning テクノロジーとLPAR(Logical Partition)
Micro-Partitioning(マイクロ・パーティショニング)テクノロジーは、IBMの仮想化技術の1つです。
POWER9(POWER5以降)はファームウェアであるPOWER ハイパーバイザ上で稼働しており、その機能を利用して物理コアを、そのまま使用する「専用プロセッサ パーティション」と、必要なコア分をまとめた「共有プロセッサパーティション」に分け、「共有プロセッサ パーティション」は更に論理的なグループ(LPAR:Logical Partition)に分けて扱うことができます。
このグループ毎にOSを導入することになります。各共有プロセッサパーティションは、更に複数の仮想プロセッサ(リソース)として扱うことができます。これが、OSが認識するプロセッサ数となります。
「共用プロセッサ パーティション」へのプロセッサ能力の割当は、時分割により、最小が物理コアの1/10で、1/100 単位で増すことができます。
1物理コア1コアで10個の仮想プロセッサに分割して利用することが可能なため、システムとしては数十台の仮想マシンを、1台のPOWER9システムに集約することも、理論上は可能となります。
仮想化ソリューション
エンタープライズ環境で多くの実績を持つIBM PowerVM、そして、オープン環境向けにはKVM(L922のみ)が選択可能です。Micro-Partitioning テクノロジーは、IBM PowerVMで利用可能です。
高いエネルギー制御機能
コアがアイドル状態に移行するのに必要な時間を1/10に短縮したり、チップ上のコントローラの制御で、コアの動作クロックと電源電圧を制御することにより、50%の電力で80%の性能を出すことができます。
また反対に、各コアの電力消費に余裕がある場合は、その電力を優先度の高い処理を行っているコアにつぎ込み、最大30%のクロックアップを行うことができます。